ในยุคที่ ข้อมูลคือทองคำ Python Library ก็เปรียบเสมือนพลั่วขุดทอง ที่จะเข้ามาช่วยให้ธุรกิจค้นพบโอกาสใหม่ๆ และสร้างความเติบโตผ่านการวิเคราะห์ข้อมูลอย่างมีประสิทธิภาพ อีกทั้งยังช่วยสร้างการตัดสินใจเชิงกลยุทธ์ และความได้เปรียบในระยะยาว บทความนี้แอดมินจะมาแนะนำ Python Libraries for Data Science ที่นักวิทยาศาสตร์ข้อมูลสมัยใหม่ควรรู้
แนะนำ 10 Python Libraries for Data Science
1. Pandas (Open-source) ไลบรารีพื้นฐานสำหรับการจัดการ และวิเคราะห์ข้อมูลแบบมีโครงสร้างเฉพาะ จัดเตรียมข้อมูลให้เหมาะสมกับประเภทของชุดข้อมูล
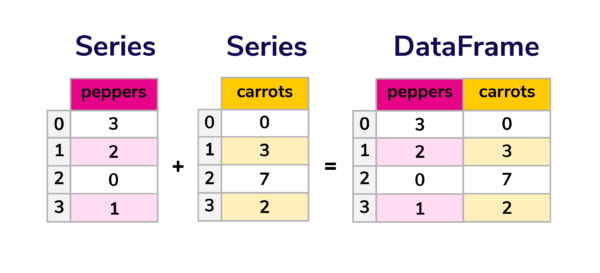
Key Features
- วิเคราะห์ข้อมูลแบบ Time-series ได้
- ผสาน และปรับรูปแบบของโครงสร้างชุดข้อมูล
- จัดการรวบรวมข้อมูลด้วย Aggregating data
- จัดการข้อมูลรูปแบบตารางด้วย DataFrames (จุดเด่น)
2. NumPy ไลบรารีจัดการ Array และเมทริกซ์หลายมิติที่มาพร้อมฟังก์ชันทางคณิตศาสตร์ ซึ่ง NumPy ได้รวบรวมแพ็คเกจพื้นฐานสำหรับการคำนวณทางวิทยาศาสตร์
Key Features
- จัดการ Array หลายมิติได้อย่างมีประสิทธิภาพ
- มีเครื่องมือเกี่ยวกับ Linear algebra และ Random number
3. SciPy สร้างบนพื้นฐานของ NumPy โดยเพิ่มฟังก์ชันเพิ่มเติมสำหรับการคำนวณทางวิทยาศาสตร์เข้าไป รองรับการคำนวณที่ซับซ้อนยิ่งขึ้น
Key Features
- ปรับวิธีการบูรณาการเชิงตัวเลข และการเพิ่มประสิทธิภาพ
- มีความสามารถในการทำ Signal processing
4. Matplotlib & Seaborn (Open-source) ไลบรารีหลักสำหรับการสร้างกราฟในภาษา Python ซึ่ง Seaborn จะมีฟังก์ชันสำหรับการสร้างกราฟที่ซับซ้อนยิ่งขึ้น เช่น Box Plots, Violin Plots และ Heatmaps ทำงานได้ดีด้วย High-level API ซึ่งทั้งสองไลบรารีสามารถทำงานร่วมกันได้เป็นอย่างดี

Key Features
- Interactive plots (Scatter, Pie, Line), 3D charts, Real-time streaming
5. Plotly ไลบรารีสร้างกราฟแบบ Interactive เชิงโต้ตอบ
6. Scikit-Learn (Open-source) ไลบรารีสำหรับการเรียนรู้ของเครื่อง (Machine learning : ML) เป็น Provider ด้านการเรียกใช้เครื่องมือแมชชีนเลิร์นนิง เพื่อช่วยให้นักพัฒนาสามารถสร้างโมเดลการทำนายผ่าน ML ที่ได้รับการฝึกอบรมไว้ล่วงหน้าแล้ว
Key Features
- Classification, Regression, Clustering, Dimensionality reduction
7. Statsmodels ไลบรารีสำหรับการวิเคราะห์ทางสถิติ ซึ่งเป็นส่วนเสริมของ Scipy มีทั้งสถิติเชิงพรรณนา การประมาณค่า และการอนุมาน ตัวอย่าง
Key Features
- มีแบบจำลองทางสถิติให้เลือกใช้
- การทดสอบสมมติฐาน
- การสำรวจข้อมูล
8. PySpark ไลบรารีที่ทำให้ภาษา Python สามารถทำงานร่วมกับ Apache Spark ได้ ซึ่งเป็นแพลตฟอร์มสำหรับการประมวลผลข้อมูลขนาดใหญ่ (Big Data) หากมีความจำเป็นต้องใช้ชุดข้อมูลขนาดใหญ่ PySpark สามารถช่วยได้
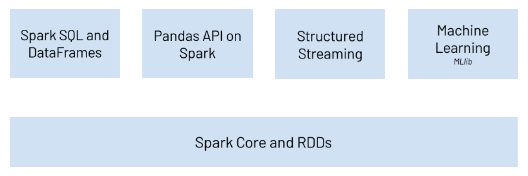
Key Features
- Big Data analytics
- Distributed computing
9. TensorFlow & PyTorch (Open-source) ไลบรารีการเรียนรู้เชิงลึก (Deep learning) เป็นเครื่องมือสำหรับใช้งานโครงข่ายประสาทเทียมที่มีความซับซ้อน (Complex neural network) หรือเป็น End-to-end platform สำหรับงานด้าน Machine learning

Key Features
- Neural networks
- Model training
- การจัดการ GPU และ TPU สำหรับการเรียนรู้ของเครื่อง
10. Dask ขยายขีดความสามารถของ Pandas และ NumPy เพื่อจัดการชุดข้อมูลที่มีขนาดใหญ่กว่าขนาดหน่วยความจำ และการทำงานแบบคู่ขนาน

Key Features
- Parallel computing
- Scalable data analysis
# Example code for Big Pandas
import dask.dataframe as dd
df = dd.read_parquet("s3://data/uber/")
# How much did NYC pay Uber?
df.base_passenger_fare.sum().compute()
# And how much did drivers make?
df.driver_pay.sum().compute()
บทสรุป
การเลือกใช้ Python Library ที่เหมาะสมกับงานวิเคราะห์ข้อมูล เปรียบเสมือนการเลือกพลัวที่เหมาะสมในการสกัดข้อมูล การเลือกใช้ Library ที่มีจุดเด่นตรงกับประเภทของข้อมูล และเป้าหมายที่ตั้งไว้ จะช่วยให้เราสามารถวิเคราะห์ข้อมูลได้อย่างมีประสิทธิภาพ และรองรับการนำไปต่อยอดได้ดียิ่งขึ้น – เมื่อใช้ไพธอนไลบรารีจัดเตรียมข้อมูลให้พร้อมต่อการใช้งานเรียบร้อยแล้ว สามารถนำชุดข้อมูลไปต่อยอดพัฒนาเป็น ML ได้ผ่านเครื่องมือฟรี LLM Locally พัฒนา Large Language Model บนเครื่องส่วนตัวต่อไปได้



